
Johdanto
Tämä artikkeli pohjautuu Joshua Stapletonin ”AI Explained” YouTube-kanavalla 18.6.2024 julkaistuun puolituntiseen videoon, jossa tutkitaan tekoälyn nykyistä tilaa ja sen tulevaisuuden mahdollisuuksia.
Sinulle annetaan seuraavassa kaksi esimerkkiä (kuva 1), jossa vasemmanpuoleisia syöteruudukkoja seuraa tulosteruudukot oikealla. Molemmissa esimerkeissä oikeanpuoleiseen ruudukkoon täydennetään neliöitä samalla kaavalla.
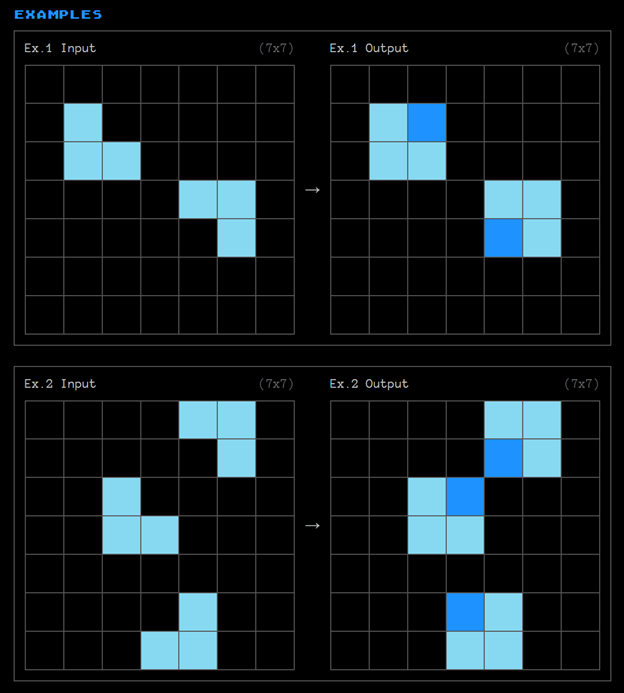
Seuraavassa kuvassa 2 sinulle annetaan testiksi lähtötilanne ja tehtävänä on päätellä edellisten esimerkkien perusteella, mikä on lopputulos.
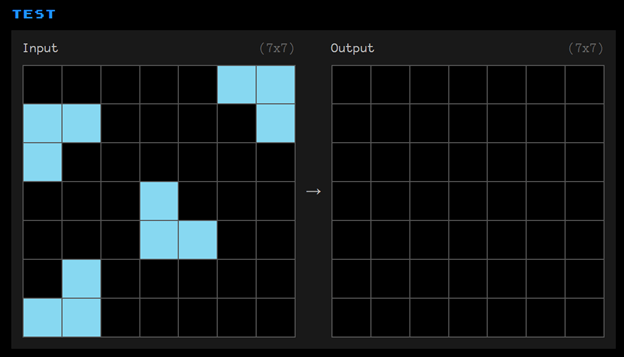
Pystyitkö päättelemään kuvan 1 esimerkkien pohjalta kuvan 2 tulosteruudukolle johdonmukaisesti rakentuvan kuvion?
Oikea vastaus on alla kuvassa 3.
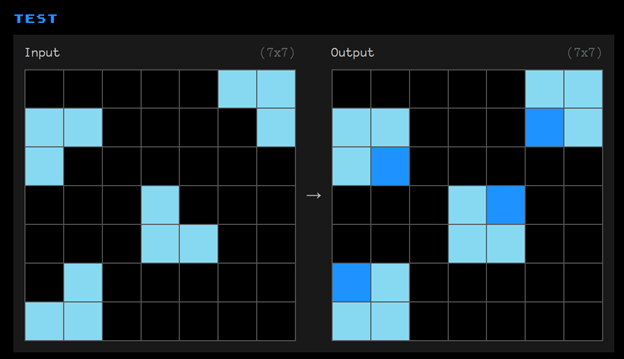
Oikeassa vastauksessa ruudukot täydentyvät alkuperäisillä vaalean sinisillä neliöillä sekä tummemman siniseksi värjätyillä neliöillä.
Abstrakti ajattelu ja tekoäly
Tämä on yksi sadoista tehtävistä, joilla testataan AGI:n eli yleistekoälyn kehittymistä ARC-AGI alustassa (ARC = Abstraction and Reasoning Corpus), joka lanseerattiin vuonna 2019 suorituskykymittariksi tekoälylle. Testit pohjautuvat François Cholletin tutkimukselle On the Measure of Intelligence. Tehtävillä mitataan kykyä päätellä tietoa, jota ei ole suoraan kerrottu tehtävässä. Ratkaisu ei ole siis suoraan laskennallisesti etsittävissä esimerkiksi neuroverkosta. Chollet ja Zapierin perustajajäsen Mike Knoop ovat luvanneet miljoonan dollarin palkinnon sille, joka kykenee ratkaisemaan tehtäväkokonaisuuden puhtaasti tekoälyohjelman avulla. Kilpailu muistuttaa Clay Mathematics-instituutin seitsemää Millennium Prize-ongelmaa, joista kustakin on myös luvattu todistajalle miljoona dollaria.
ARC-AGI-tehtävä on yllättävän vaikea nykyisille state-of-the-art tekoälymalleille. Ne epäonnistuvat tehtävässä, koska tehtävät ja ratkaisut eivät ole osa niiden koulutusdataa ja ne eivät osaa yleistää esimerkeistä löytyvää lainalaisuutta.
Tehtävä havainnollistaa nykyisten tekoälymallien rajoituksia tehdä päätelmiä ja yleistyksiä. Kyseessä ei siis olisi pelkästään visuaaliseen syötteeseen rajoittuva ongelma, vaan syvempi haaste, joka koskee myös kaikkia lippulaivakielimalleja kuten GPT-4 Omni, Gemini 1.5 Pro sekä Claude 3 Opus. Parhaimmat tulokset on toistaiseksi saatu hyödyntämällä laajoja kielimalleja (LLM), mutta matkaa keskiarvoiseen ihmisen suorituskykyyn on vielä paljon. On syytä epäillä, että edellä mainitun kaltaisen ongelman ratkaisu ei onnistu yksinkertaisesti laajentamalla malleja nykyisellä menetelmällä eli lisäämällä opetusmateriaalin datan tai parametrien määrää. arcprize.org tiimi on suhteellisen varma siitä, että onnistumiseen asetettu 85 % raja on itseasiassa saavuttamattomissa. Viiden vuoden aikana parannusta on tapahtunut vain kahdestakymmenestä prosentista kolmeenkymmeneen neljään prosenttiin. Väitteen mukaisesti ratkaisuihin vaadittava aito päättely ei onnistuisi nykyisillä tekoälymalleilla, joten he uskaltavat luvata julkisesti noinkin ison summan rahaa. Toisaalta tämä on omiaan provosoimaan uusien mallien innovointia.
Puolitoista vuotta sitten tutkimme teoreettisen fysiikan tohtori Matti Pitkäsen kanssa hänen Topologinen Geometrodynamiikka (TGD) teoriaa kielimallien avulla. Huomasimme hyvin nopeasti, että GPT-3.5 ja myöhemmin ilmestynyt GPT-4 eivät kyenneet käsittelemään aihetta juuri ollenkaan. Tieto TGD:stä oli kyllä kielimallissa ja se tunnisti TGD:n fundamentaalifysiikan teoriaksi, mutta sen jälkeen kaikki yksityiskohdat sekoittuivat eikä alkeellinenkaan teoreettinen päättely ja matemaattisten yhteyksien luominen onnistunut. Eli ARC-AGI-mittaria vastaavat heikot tulokset olivat nähtävissä helposti jo silloin.
Lopulta löysin kuitenkin yhden kulman, jolla kielimallia saattoi käyttää teorian tutkimisessa. Takaperin suunnittelun (reverse engineering) idea tuntui toimivan. Siinä muodostetaan ensin teoriaan liittyviä täsmällisiä lauseita, annetaan ne kielimallille pureskeltavaksi ja pyritään interaktiivisesti keskustelemaan sisällöstä. Tämä auttaa hahmottamaan, miten hyvin lauseiden merkitys avautuu kielimallille ja kuinka hyvin se pysyy teemassa, joka taas indikoi parhaassa tapauksessa siitä, miten hyvin lauseet avautuvat myös lukijalle. Tämän pohjalta lauseiden muotoa saattoi sitten selkeyttää. Kielimallien toiminta on tilastolliseen menetelmään pohjautuva ja sitä kautta tietoa tasapäistävä, joka vaikuttaa taas tuottavan tekstiä, joka on keskivertoisesti helpompi ymmärtää. Käytin tätä tekniikkaa ahkerasti kirjoittaessani vertaisarvioidun kirjan TGD:stä, jonka Holistic Science Publications julkaisi keväällä 2024.
AI ei ole maaginen ratkaisu kaikkiin ongelmiin. Mutta onko AI edes lähellä sitä, että se vastaisi luovan työn ammattilaisen tai kokeneen tohtoritutkijan kompetenssia alalla kuin alalla? Yleisesti ajatellaan, että AGI on systeemi, joka voi automatisoida suuren osan ekonomisesti hyödyllistä työtä. Cholletin mukaan oikeampi määritelmä on systeemi, joka voi tehokkaasti hankkia uusia taitoja ja ratkaista avoimia ongelmia.
Tekoälyn nykyiset haasteet
Monet uskovat, että spesialisoitunut tekoäly (Artificial Intelligence) on yliarvostettu. Yleistekoäly (Artificial General Intelligence), jota joskus kutsutaan myös vahvaksi tekoälyksi, joka kykenee johdonmukaiseen ihmistä imitoivaan ajatteluun, vanhan tiedon pohjalta yleistämiseen ja uusien ideoiden keksimiseen sekä suunnitteluun, on vain hypeä. Toiset, kuten somevaikuttaja David Shapiro uskovat, että AGI on jo täällä tai ainakin pian tulossa – syyskuussa 2024 on Shapiron yltiöpäinen arvio. Perusteluksi esitetään muun muassa, että kaupalliset yritykset kehittävät malleja piilossa kuluttajilta. Oletettavasti yrityksillä on useita eri tulevaisuuden versioita kehitteillä ennen kuin niistä vanhimpia julkaistaan. Google ja OpenAI olivat kehittäneet kielimalleja jo vuosia ennen kuin OpenAI onnistui luomaan ChatGPT-läpimurtosovelluksen massiivisella tekstiaineistolla opetetulle neuroverkolle, joka hyödynsi jo olemassa olevaa transformer-arkkitehtuuria.
Onko yleistekoälyyn vaadittavalle läpimurrolle kuitenkaan todellisia perusteita vai pitäisikö meidän olla konservatiivisempia ja uskoa mieluummin siihen, millaista teknologiaa näemme oikeasti olevan olemassa? Joillekin tämä voi olla tärkeä kysymys, joka täytyisi ratkaista etukäteen, jotta vältymme illuusion paljastumisen häpeältä ja resurssien tuhlaamiselta, mutta todellisuudessa emme tietysti voi tietää ennen kuin jälkikäteen, mitä meille on lopulta tarjottu globaalia ekonomiaa pyörittävien yritysten toimesta.
Tekoälyllä on myös useita yhteiskunnallisia haasteita. Ne ulottuvat yksityisyyden suojasta ja immateriaalioikeuksista ihmiskunnan tulevaisuuden huoliin, katteettomista lupauksista ja viivästyneistä julkaisuista aina yhteiseen energia- ja kognitioresursseja syövään tragediaan. AI-agentit ja chatbotit keskustelevat keskenään palstoilla, keräävät tykkäyksiä peukaloidakseen algoritmeja ja ohjatakseen huomiota sekä liikennettä, milloin minnekin. Ihmisiä jää väkisinkin haaviin tässä virtuaalipelissä. Epäilen, että harvat kokevat mielihyvää siitä, kun keskustelukumppanin “persoonallisuus” selviää – se olikin jono painoarvoja. Ihmiskieltä helposti matkivat kielimallit suoltavat sähköposteja, tekstiviestejä, kommentteja ja websivusisältöjä, joiden ainoa tarkoitus on pettää herkkäuskoisia ihmisiä ja kavaltaa rahaa – deepfaken mahdollistamista identiteettivarkauksista puhumattakaan. Vastapainoksi tämä vaatisi sen, että ihmiset todellakin opettelevat arvioimaan kriittisesti kaikkea lukemaansa ja näkemäänsä. Sisälukutaidon merkitys kasvaa huimasti tulevaisuudessa. Se on jo nyt merkittävä avu tietoyhteiskunnan kansalaisille.
Tekoälyn generoima moska luo sisällöllään yleistä hämmennystä. Tietoa tärkeänä pitävissä ympäristöissä tulee entistä vaikeammaksi erottaa tosi fiktiosta ja vääristellystä informaatiosta. Sisällön varmistamiseen kuluu yhä enemmän aikaa. On tutkittu, että viime vuoden aikana tiedejulkaisuihin päätyvät artikkelit sisältävät tekoälyn tyypillisesti generoimia fraaseja kuten “delve,”, “intricate,” “multifaceted,” “pivotal” ja “not only x but y” nyt enemmän kuin koskaan aikaisemmin. Tekoälyn avulla tenteistä voivat suoriutua läpi henkilöt, jotka eivät todellisuudessa ymmärrä opiskelemastaan aiheesta juuri mitään.
Brittiläinen tekoälytutkija, Googlen DeepMindin perustajajäsen, Sir Demis Hassabis, väitti Gemini-kielimallin julkaisun yhteydessä marraskuussa 2023 sen päihittävän ihmisasiantuntijat viidelläkymmenellä eri alalla. Samanlaista hypeä on hehkutettu toissa viikolla julkistetulle Apple Intelligence-tuotteelle. Applen toimitusjohtaja Tim Cook myönsi kuitenkin, että heidänkin AI hallusinoi. Miksi? Koska he käyttävät Elon Muskin harmitukseksi palvelunsa taustalla GPT-4 kielimallia. OpenAI:n ChatGPT komentokentän alla lukee edelleen: “ChatGPT voi tehdä virheitä. Suosittelemme tarkastamaan tärkeät tiedot.” Ristiriitaisia tunteita herättää myös se, että Apple nimesi tekoälytuotteensa Apple Intelligence eli lyhennettynä AI. Kuvitteleeko Apple, että kilpailu voitetaan pelkällä semantiikalla? Kumpi hallusinoi lopulta enemmän, AI vai ihminen?
Voidaan väittää, että kielimallit eivät ole suunniteltu olemaan oikeassa, vaan pikemminkin olemaan luovia. Ne ovat työkaluja, jotka voivat tuottaa, muovata ja stilisoida sisältöä, mutta eivät välttämättä ole luotettava tietolähde eivätkä ne toimi tiedon tai sen johdonmukaisuuden tarkastajina. Jotkut siis pitävät virheitä osoituksena luovuudesta. Toisinaan virheherkkyys on kuitenkin niin räikeää, että AI-työkalut ovat käytännössä hyödyttömiä monella kriittisellä ja vakavalla alalla.
Yhtälö tuntuu vaikealta ihmisellekin. Toisaalta pitäisi pystyä luomaan uutta oivaltavaa sisältöä ja toisaalta kyetä toistamaan vakiintunutta faktaa sekä tuottamaan luotettavaa virheetöntä sisältöä. Uusi vaatii kuitenkin testaamista ja varmistusta. Voiko AGI:lla ajatella olevan resursseja koostaa taustalla tieteentekijäryhmän, joka validoi teoksen vertaisarviointiprosessin kautta? Tulevatko AGI-agentit korvaamaan lopulta arvioijatkin? Ainakaan ei voi odottaa, että AGI:n lonkalta heittämä vastaus sisältäisi monimutkaisen arviointiprosessin, koska se vaatii huomattavasti aikaa. Silloin puhuttaisiin jo superälykkyydestä, seuraavasta vaiheesta AGI:n jälkeen. Kohtuullisuuden nimissä voimme kuitenkin jo nyt odottaa meille tuttuihin säännönmukaisuuksiin ja lainalaisuuksiin perustuvaa johdonmukaisuutta tulosteessa.
Tietysti on jo olemassa menetelmiä kielimallin tulosten tarkistamiseen, kuten tekoälysovelluksen sisälle automatisoidut Internet haut, joista Perplexity.ai on tunnetuin sovellus. Mutta tämä vain osoittaa, että kielimallit itsessään ovat vielä kaukana AGI-tavoitteesta. On aiheellista kysyä, onko kielimalleilla sellaisenaan mitään teknisiä edellytyksiä saavuttaa tällaista tavoitetta? Vai olisiko se pikemminkin kombinaatio erilaisia teknologioita, jotka toimivat saumattomasti keskenään?
Näyttävästi AI-edelläkävijän roolia viime vuoden esittänyt Microsoft ja äsken jälkijunassa AI-tuotteensa julkistanut Apple ovat integroimassa tekoälyyn perustuvaa työpöytäkäyttäytymistä kuvaruutukaappauksina tallentavaa hakutoiminnallisuutta käyttöjärjestelmätasolle. Tämä on yhtä aikaa sekä innostanut että huolestuttanut käyttäjiä. Jokainen ymmärtää, miten turhauttavaa on hakea loputtomien eri tiedostojen joukosta juuri haluamaansa tietoa. Kontekstia ja aikaleimoja reaaliaikaisesti lukeva AI on tulevaisuuden käyttöjärjestelmän ydinohjelmistokomponentti, joka ratkaisisi tiedon hakuun ja sen esittämiseen liittyviä ongelmakohtia. Mutta minne se kaikki henkilökohtainen tekoälyn pureksima tieto lopulta päätyy?
Apple on pyrkinyt vakuuttamaan, että vaikka heidän AI-ratkaisunsa käsittelee tiedon osittain pilvipalveluissa, tallennus ja prosessointi on kuitenkin salattu niin, että yksityisyyden suoja säilyy täydellisesti. Applen mukaan suojaus voidaan tarvittaessa verifioida riippumattomien kolmansien osapuolien avulla.
Tässä vaiheessa nämä ovat kuitenkin lupauksia, joiden lunastusta saamme odottaa, kunnes nyt enemmän säännöksi kuin poikkeukseksi muodostunut “julkaistaan myöhemmin tänä vuonna” toteutuu. Microsoft ehti jo lykätä edellä mainitun Recall-toiminnon tuloa viikoilla. Odottelemaan on jääty myös OpenAI:n GPT-4 Omnin multimodaaleja ominaisuuksia sekä videogenerointiohjelmaa. Entä Googlen “US-only” hakutuloksia tulkkaava AI Overviews? Lykätty hallusinaatioepäilyjen ja käyttäjien esittämän disinformaation takia. Tämä alkaa kuulostamaan kohta rikostarinalta.
Sitten on vielä puhtaaseen fysiikkaan ja rahaan liittyvä ongelma. Tekoälyn mahdollistavat tensorilukuja murskaavat prosessorit vaativat pian ydinvoimaloittain energiaa, jos niiden hyödyt ja palvelut halutaan kaikkien ihmisten ulottuville. Silti OpenAI:n toimitusjohtajan Sam Altmanin mielestä tulevaisuuden kielimalliin pääsyn pitäisi kuulua perustoimeentulon piiriin.
Liialliset lupaukset, viivästyneet toimitukset, kestävän kehityksen haaste, yksityisyyden loukkaukset ja akateemisen eheyden uhka, kaikki nakertavat tekoälyn uskottavuutta, mutta eivät tunnu kuitenkaan sen kulkua kokonaan estävän. Juna on laitettu liikkeelle ja satojen miljardien sijoitukset työntävät veturia vääjäämättä eteenpäin. Jopa suitsia trendille asettavan EU:n kohtalo on joko tulla perässä tai hävitä taisto innovaatiokehityksessä, jota AI muualla maailmassa inspiroi. Aina löytyy uusia tilastollisia kuvaajia, jotka esittävät kuoppaisenkin tien lopulta johtavan kiihtyvään kehitykseen, jonka päätyä ei usein näytetä, mutta jossa tuomiopäivän ennustajien mielestä odottaa musertava loppupiste, teknologinen singulariteetti.
Missä tekoäly loistaa?
Entä sitten edut? Ovatko AI ja generatiiviset kielimallit kyenneet antamaan vielä mitään hyödyllistä lukuun ottamatta kuva-, ääni-, video- ja tekstitulvaa, joiden perusteella kuka tahansa voi nyt esiintyä kirjailijana, käsikirjoittajana, säveltäjämuusikkona ja graafikkona kaikkia yhtä aikaa? Joka päivä keskustelupalstoilta löytyy henkilö, joka on ensikertaa silmin vaikuttunut AI-generaattoreiden kyvystä luoda taiteellisia teoksia, jotka muuten olisivat henkilön taitojen ulottumattomissa. Hyvin usein teoksia tarkemmin tarkasteltaessa niistä löytyy paljon yksityiskohtia, jotka joka tapauksessa paljastaisivat tekoälyn osallisuuden, mutta lähes automaattisesti luodut teokset ovat kieltämättä hämmästyttäviä, kun vertaa missä olimme puolivuosikymmentä sitten. Mieti esimerkiksi sitä, millä tasolla nytkin arvioimme kielimallien toimivuutta. Se on kuin toiselta planeetalta verrattuna siihen, miten aihetta käsiteltiin 1990-luvulla.
AI:n kyvyt lumoavat käyttäjän joksikin aikaa, kunnes jos teosta alkaa viimeistelemään, huomaa, että joutuukin tekemään kohta täyspäiväisesti töitä laadukkaan uniikin lopputuloksen aikaansaamiseksi. Jossain näissä maisemissa kulkee se raja, jossa jotkut päätyvät AI:ta hyödyntäviksi taitelijoiksi ja toisilta loppuu innostus. Erottua voi joukosta myös sillä, että nimenomaan ei käytä AI:ta kuvien teossa, kuten kauneusjätti L’Oreal on mainoksissaan väittänyt. Se ei tarkoita, etteikö yritys käyttäisi AI:ta moneen muuhun, kuten esimerkiksi aivoriihiin ja analytiikkaan.
Yksi alue, jossa AI on kiistämättä aiheuttanut mullistuksia, on ohjelmointi ja tekninen dokumentointi. Jo ennen kielimalleja jokaisen ammattikuntaansa kunnioittavan ohjelmoijan tavoitteena on ollut automatisoida kaikki toistuva koodin tuottaminen. Kielimallit ovat merkittävällä tavalla helpottaneet asiaa. Kielimallit ovat oivallisia esittämään variaatioita ja vaihtoehtoja, tekemään listoja ja taulukoita, klassifioimaan, löytämään sentimenttejä sekä tuottamaan monenlaista eri syntaksia. Sen sijaan että ne kykenisivät suunnittelemaan, ne kykenevät olemaan suunnittelijan apuna. Sen sijaan, että ne loisivat kokonaan uutta, ne voivat nopeasti tuoda esiin jo olemassa olevia ratkaisuja, joiden keräämiseen kuluisi valtavasti aikaa. Ne voivat ehdottaa miten aihetta voi lähestyä jo olemassa olevilla menetelmillä, jotta sieltä voi ehkä pusertaa ulos jotain uutta. Ne voivat indikoida onko jokin esitetty asia uutta, tunnettua toisinajattelua vai vakiintunutta tietoa. Uusi tieto on jossain määrin suhteellista, koska henkilölle, joka ei ole opiskellut jotain aihetta, kielimalli voi kertoa paljonkin uutta tietoa. Vain asiantuntijat voivat lopulta arvioida uutuuden.
AGI:n määritelmä vaatisi sen, että systeemi kykenee toimimaan itsenäisenä tuotteliaana kollegana, mutta tällä hetkellä joudumme tyytymään raajarikkoon AI-apuriin. Vaikka tieteellisessä kontekstissa kielimallien merkitys on kyseenalainen, niiden avulla on kuitenkin mahdollista sparrata omaa tietouttaan, kehittää tietämystä ja asiantuntemusta tutkimusalueestaan sekä helpottaa puhtaaksikirjoitustyötä esimerkiksi LaTeX-formaattiin, varsinkin jos kohdekieli on englanti eikä se ole kirjoittajan äidinkieli.
Entäpä jos olisit sokea, antaisitko anteeksi satunnaisen hallusinoinnin AI:lla ja olisit kiitollinen siitä, että se voi kuvailla sinulle ympäröivää maailmaa vuorovaikutteisesti reaaliajassa? Tällaisia esimerkkejä OpenAI ja Google näyttivät edellisissä julkistustilaisuuksissaan. Tähänkin toki liittyy vaara, että teknologiaan syntyy liian suuri luottamus. Ei ole mukava kompastua lammikkoon, jos AI ei kykenekään ajoissa kertomaan edessä olevia esteitä.
Meidän on tietenkin muistettava, että AI ja neuroverkot ovat paljon enemmän kuin pelkät laajat kielimallit. Nämä termit ovat joka tapauksessa menneet täysin sekaisin puhekielessä viime vuosina. Uusi tutkimus Nature-lehdessä osoitti, miten generatiivisia kilpailevia verkkoja (GAN) voidaan käyttää ennustamaan ennen testaamattomien kemikaalien vaikutuksia hiiriin. AnimalGAN tässä tapauksessa kykeni simuloimaan virtuaalista eläinkoetta tuottaakseen profiileja, jotka olivat samankaltaisia kuin perinteisistä eläinkokeista saadut tulokset. TLDR; merkittävää ei ole pelkästään se, että generoidut ennusteet olivat vähemmän virheellisiä, vaan ne tuotettiin paljon nopeammin. Tämä on ainakin yksi varovainen askel kohti eläinkokeiden loppua. Tämän lisäksi muutama päivä sitten julkaistiin tutkimus, jossa Harvardin Yliopisto ja Google DeepMind rakensivat virtuaalisen jyrsijän, jota AI ohjasi hermotoiminnan tasolla asti.
Vanhan koulukunnan konvoluutioneuroverkot ovat erinomaisia kuvantunnistuksessa. Ne ovat esimerkiksi mahdollistaneet aivohalvausdiagnoosien tekemisen lääkäreiltä paljon nopeammin, joka on kolminkertaistanut parantuvien potilaiden määrän. Spesialisoituneisiin tehtäviin valjastettu tekoäly ja koneoppimisalgoritmit ovat lunastaneet lupauksensa ja hyödyllisyytensä, siitä ei ole kahta sanaa. Kysymys AGI:sta on kuitenkin aivan oma alueensa.
Yleistekoälyn saavuttamisen haasteesta
Lyhyesti sanottuna ongelma on seuraava: Jos kielimallit eivät ole nähneet tarkkaa ratkaisua johonkin ongelmaan koulutusdatassaan, ne eivät pysty antamaan oikeata vastausta. Siksi mallit epäonnistuvat tässä haasteessa. Mallit eivät ole yleisälykkäitä. Kielimallit epäonnistuvat uudessa tuoreessa testissä, jossa sille annetaan vain pari esimerkkiratkaisua, kuten vaikkapa kuvassa 4.
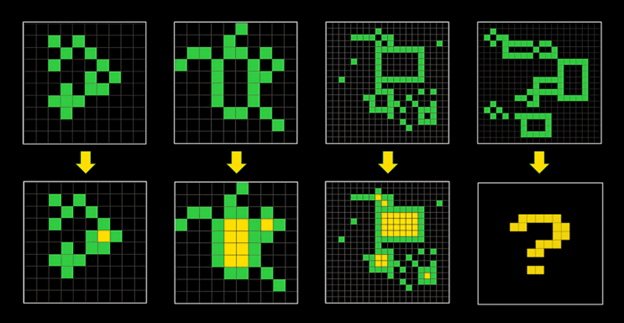
AI-tuotteita markkinoivat yritykset kuitenkin näyttävät usein tilastoja, joissa ne vaikuttavat suoriutuvan esimerkiksi koulukokeista hyväksyin arvosanoin. Miten mallit ovat pystyneet suoriutumaan niin hyvin muista tunnetuista suorituskykytesteistä (BIG-bench, HumanEval, GSM8K, HellaSwag, MMMLU, MT-Bench, GPQA, DROP)? No, ne voivat ”muistaa” tiettyjä päättelyketjuja, joita ne ovat “nähneet” aiemmin. Se riittää tietyissä olosuhteissa saamaan oikean vastauksen. Joten ne voivat muistaa tiettyjä päättelymenetelmiä, kutsutaan niitä vaikkapa ohjelmiksi, mutta ne eivät voi luoda niitä. Testeillä on voitu kartoittaa tekoälyn kehittymistä staattista tietoa vaativien tehtävien parissa, mutta ARC-AGI tavoite on testata tekoälyn dynaamisempaa päättelykykyä. Siinä mielessä nykyiset testit ovat tarkoituksella? vinoutuneita, että ne eivät tuo esiin pullonkauloja.
Kielimallien kouluttaminen uudella datalla vie parhaimmillaan kuukausia aikaa, eli reaaliaikainen oppiminen on täysin mahdotonta. Vain konteksti-ikkunassa olevaa dataa ja systeemipromptia hyödyntämällä ja sitä päivittämällä voidaan reaaliaikaisesti ohjata mallin generoimaan haluttua tekstiä, ja siinä mielessä “opettaa,” mutta se ei ole sama asia kuin uuden oppiminen kielimallin tasolla. Vielä vähemmän se on sama kuin kyky oppia uutta.
Miksi emme sitten kouluttaisi kielimalleja kaikilla mahdollisilla päättelymenetelmillä, syöttäisi sille synteettisesti generoitua dataa mistä tahansa skenaariosta, johon se saattaa törmätä, eikö se riittäisi saavuttamaan yleistekoälyn? Cholletin mukaan muistaminen yksinään ei riitä, koska emme näe yhdellä kertaa koko karttaa maailmasta. Jos elämäsi olisi staattinen jakauma, voisit yksinkertaisesti kokeilla brute force-menetelmällä kaikkia mahdollisia käyttäytymismalleja. Voit ajatella älykkyyttä polun etsimisalgoritmina tulevien tilanteiden avaruudessa, kuten strategiapelien kehityksessä. Sinulla on 2D-kartta, jossa on osittain tietoa, sumu peittää joitain alueita. On alueita, joita et ole vielä tutkinut, et tiedä niistä mitään, ja sitten on alueita, jotka olet tutkinut, mutta tiedät vain, millaisia ne olivat aiemmin. Ajatellaan nyt mahdollisten tulevien tilanteiden avaruudellisten pisteiden sijasta, miten ne yhdistyvät toisiinsa. Älykkyys on polun etsimisalgoritmi. Kun asetat tavoitteen, se kertoo, miten sinne päästään optimaalisesti, mutta se on rajoitettu tiedoilla, joita sinulla on. Se ei voi etsiä polkua alueella, josta et tiedät mitään. Jos sinulla olisi täydet tiedot kartasta, voisit ratkaista polunetsimisongelman yksinkertaisesti muistamalla kaikki mahdolliset polut, kaikki pisteiden A ja B väliset yhdistelmät. Mutta todellisuudessa et voi tehdä sitä, koska et tiedä, mitä tulevaisuudessa tapahtuu. Joten jos AGI kohtaa uusia tilanteita, kuten tällaisessa tuntemattomia pisteitä sisältävässä kartassa, sen on sopeuduttava lennossa tilanteeseen, yleistettävä tietoa ja sen pohjalta täytettävä aukko.
Noam Brown OpenAI:sta on optimistinen siitä, että laajat kielimallit onnistuvat tässä yleistävän tiedon ongelmassa. Samoin vähän aikaa sitten OpenAI:sta erotettu Leopold Aschenbrenner on 165-sivuisessa esseessään SITUATIONAL AWARENESS: The Decade Ahead esittänyt, että datan ja parametrien laajentamisen avulla on saavutettavissa vielä merkittäviä edistysaskeleita. Tällä hetkellä kuitenkaan ilman esimerkkejä eli käyttämällä zero-shot-menetelmää, mallit eivät yleistä näkemäänsä uuteen. Ei väliä millä neuroverkkoarkkitehtuurilla tai parametrien määrällä tätä on testattu.
Tekoälymallit ovat datanälkäisiä, toisin kuin ihmislapsi, joka oppii tehokkaasti yhdestä näytteestä. Lapsi voi nähdä yhden kuvan kamelista ja muistaa sen termin elämänsä ajan. Kielimallit taas vaativat eksponentiaalisesti enemmän dataa oppiakseen uutta. Pian tulee kysymykseen, löytyykö maailmasta enää lisää hyödyllistä dataa, jolla tätä vaatimusta voidaan täyttää ja toisaalta, sisältääkö hiljainen dokumentoimaton tieto jotain sellaista, joka auttaisi kielimalleja parempaan tulokseen.
Kuusi tapaa parantaa nykyisten kielimallien päättelykykyä
Vaikka nykyiset tekoälymallit ovat AGI:n kannalta katsottuna monilta osin kömpelöitä ja niitä voidaan käyttää väärin, tilannetta on mahdollista parantaa ehkä merkittävästikin. Seuraavaksi esitellään kuusi tapaa, jotka voivat tuoda tämän päivän peruskoulu- ja lukiotasoiseksi luokitellun tekoälyn lähemmäksi yleistekoälyä, jolloin järjestelmä kykenee toimimaan itsenäisesti ja luontevasti esimerkiksi tietojenkäsittelytyöntekijän kollegana.
Parannettavat osa-alueet:
- Koulutetaan malleja yhdistämään pääteltyjä osia monimutkaisemmiksi kokonaisuuksiksi.
- Autetaan malleja tunnistamaan virheelliset askeleet päättelyketjussa ja sen avulla parantamaan ohjelmien laatua.
- Annetaan malleille runsaasti esimerkkejä halutusta tehtävästä, jotta ne oppivat paremmin.
- Hienosäädetään malleja testiajon aikana, jolloin ne keskittyvät paremmin haluttuun tehtävään.
- Hyödynnetään perinteistä symbolista logiikkaa tekoälyn kehittämisessä.
- Etsitään ja otetaan huomioon ihmisasiantuntijoiden tietoa, jota ei ole kirjallisesti dokumentoitu.
I. Ehkä mallit eivät osaa päätellä, mutta jos ne pystyvät paremmin yhdistämään päättelypalikoita monimutkaisemmiksi kokonaisuuksiksi, voisiko se riittää? Naturen artikkelissa Human-like systematic generalization through a meta-learning neural network tutkijat osoittavat tämän periaatteessa mahdolliseksi 1,4 miljoonan parametrin transformeriin perustuvalla mallilla. He väittävät tulosten osoittavan, että vakioneuroverkkoarkkitehtuuri, joka on optimoitu kompositionaalisille taidoille, voi jäljitellä ihmisen systemaattista yleistämisajattelukykyä. Tutkimuspaperin johtava kirjoittaja Brenden Lake on maininnut, että vastaus parempaan tekoälyyn ei todennäköisesti ole pelkästään koulutusdatan lisäämisessä, vaan koulutusstrategioiden monipuolistamisessa. Vertaa tutkijoiden käyttämää huomattavasti pienempää parametrilukua GPT-4 mallin 1,8 miljardiin, joka antaa reilusti varaa parantamiseen.
II. Koska kielimallit vaikuttavat sisältävän jonkinasteisia päättelyketjuja ja “ohjelmia”, mutta toisaalta niiden löytäminen on vaikeaa, niin mitä menetelmiä voisi käyttää löytääkseen nämä “ohjelmat” kielimalleista helpommin? Sarja papereita (PRM, OmegaPRM, ORM, MCTSr, CoT, Regan-Gournail-Oka) on julkaistu viime aikoina päättelyn parantamiseksi kielimalleissa. Pähkinänkuoressa kyse on siitä, että voit kouluttaa mallin tunnistamaan virheelliset askeleet päättelyketjussa, poimimaan huonot ohjelmat ja filtteröimään ne pois tuloksesta. Tämä niin kutsuttu “Let’s verify step by step”-menetelmä vaati ihmisen annotaatiota, mutta Googlen DeepMind-ryhmä keksi tavan, jossa automaattisesti kerätään tulokset, jotka johtavat oikeaan vastaukseen, sekä kontrastoidaan ne väärin johtaneiden tulosten kanssa. He kouluttivat palkkiomallin, ikään kuin valvojan, joka analysoi jokaisen askeleen kielimallin tuottamissa tuloksissa. Palkkiomalli varoittaa kielimallia, kun se käyttää virheellistä tai sopimatonta ohjelmaa. Tällä lähestymistavalla on päästy 50 % tuloksista 70 % onnistumiseen matemaattisissa tehtävissä. Menetelmän rajoitukset kuitenkin näkyvät jo siinä, että kun ratkaisuyritysten määrää nostetaan sataan, hyödy suhteessa suorituskykyyn ja tuloksiin alkaa heiketä. Kuitenkin periaate on selvästi todettu: Ei tarvitse luottaa pelkästään kielimalliin löytämään oikeaa ja tarvittavaa ohjelmaa haasteen ratkaisemiseksi. Voimme auttaa kielimallia matkalla tavoitteeseen.
Kielimallien hallusinoinnilla on positiivisiakin puolia. Monimuotoisten variaatioiden luominen on välttämätöntä, jotta ulkoinen validointijärjestelmä voi simuloida erilaisia tilanteita. Jason Mahin, Dr. Eureka-paperin kirjoittajan mukaan, jos kielimallilla ei ole kykyä harhailla, eli se olisi aina deterministinen, simulointimenetelmä ei toimisi, koska kielimalli voisi tuottaa vain yhden ehdokkaan per iteraatio. Kun kielimalli harhailee, teknisesti ottaen se on vain näyte todennäköisyysjakaumasta. Sen tuottama teksti on harhaa vain, jos se ei ole vastaa sitä, mitä me ajattelemme, että sen pitäisi tuottaa. Sisäisesti jokainen tuloste kuvaa vain todennäköisyysjakaumaa.
Mutta jos ajattelemme suurten kielimallien tai minkä tahansa perustavan mallin käyttötapauksia, esimerkiksi tieteellisessä kontekstissa, haluamme, että tekoäly pystyy ehdottamaan esimerkiksi 10 erilaista ratkaisumallia. Onko mahdollista, että voimme kääntää harhailut heikkoudesta vahvuudeksi? Maailman ykkösteknologiajätiksi ryminällä noussut Nvidia ja muut työskentelevät ahkerasti selvittääkseen sen.
III. Entä sitten kielimallien opettaminen lennossa? Tätä Chollet kutsuu tätä aktiiviseksi päättelyksi, ja se on saavuttanut parhaan onnistumisprosentin 34 % ARC-AGI-haasteessa. Tärkein oivallus on käyttää hienosäätöä ennen testiä. Kun malli näkee kolme esimerkkiä, kuten kuvassa 4, esimerkeistä saatava signaali ei riitä opettamaan tapaa ratkaista neljäs tapaus. Sen sijaan voit generoida esimerkiksi GPT-4-kielimallilla kolmen esimerkin pohjalta useita synteettisiä esimerkkejä, jotka jäljittelevät alkuperäisiä. Näitä esimerkkejä käytetään kielimallin hienosäätöön.
Chollet kuvaa tätä strategiaa seuraavalla tavalla: Useimmiten, kun käytät kielimallia, se tekee staattista päättelyä. Malli on jäädytetty, ja sinä vain annat sille kehotuksia ja saat vastauksen. Malli ei opi mitään lennossa. Sen tila ei sopeudu käsillä olevaan tehtävään. Sen sijaan voimme jokaisessa testiongelmassa hienosäätää kielimallia tuolle tehtävälle, ja se todella avaa paremman suorituskyvyn. Tällä voidaan kiertää kielimallien yksi keskeisistä rajoituksista, joka on aktiivisen päättelyn puute.
Päättely on kykyä tehdä synteesi lennosta, kun kohtaat pulman, johon sinulla ei ole jo valmista ohjelmaa ratkaistaksesi sen. Tämä on dramaattisesti vaikeampaa kuin vain oikean muistettavan ohjelman hakeminen ja sen käyttäminen.
Vaikka laajojen kielimallien Akilleen kantapää on abstraktissa päättelyssä, niin niiden kykyjen ylärajoja ei ole tämän perusteella vielä löydetty.
IV. Voisimme käyttää kielimalleja perinteisten symbolisten järjestelmien kanssa. Ehkä neuroverkkojen ja perinteisten symbolisten ohjelmallisten järjestelmien yhdistelmä on parempi kuin kumpikaan yksinään. Kielimallit voivat toimia ideageneraattoreina, joita maadoitetut symboliset järjestelmät voivat sitten tarkistaa. Symboliset järjestelmät toimivat silloin eräänlaisina kirjanpitäjinä. Symbolisen järjestelmän palautteella voidaan kehottaa kielimallia uudelleen ja se keksii mahdollisesti paremman suunnitelman. Eräässä tutkimuksessa GPT-4 voi saavuttaa 82 % onnistumisen tällä lähestymistavalla. Menetelmällä on myös saavutettu parannuksia matematiikkaolympialaisten geometriaongelmissa. Tosin tässä tapauksessa käytettiin kielimalleista poikkeavaa neuroverkkoa ja symbolista systeemiä hybridinä.
V. Viidennessä lähestymistavassa kutsutaan erillistä neuroverkkoon pohjautuvaan järjestelmää, jolle on opetettu erikoistuneita algoritmeja. Sitten tämä kiinteä optimoitu tietämys annetaan vuorostaan kielimallin kouluttamisen yhteydessä valmiina vektoriupotuksina koulutusdataan. Tavoitteena on se, että kielimallista tulee sujuva sekä tekstin että algoritmillisten ohjelmien kielellä, joka voisi auttaa loogisessa päättelyssä.
VI. Hiljainen tieto. Paljon siitä, mitä ihmiset tekevät ja miten ihmiset päättävät, ei ole kirjoitettu ylös teksteiksi. Matematiikan kuuluisuus Terence Tao sanoo, että paljon hänen alueensa erityistiedosta on jollain tavalla jumissa yksittäisten matemaatikkojen päässä, ja vain pieni osa siitä tehdään eksplisiittiseksi. Matemaatikkojen intuitiota ei juurikaan ole tallennettu painettuihin lehtiin, vaan se esiintyy keskusteluissa matemaatikkojen välillä, luennoilla ja siinä, miten opiskelijoita neuvotaan.
Olen miettinyt tätä myös TGD-teorian kanssa tutkimusta tehdessäni. Suurin ongelma kielimallien osalta voi olla juurikin siinä, että niille ei ole kerrottu tarpeeksi tarkkaan sitä prosessia, jolla TGD-teoriaan on päästy. Vuosikymmenien aikana kehittyneiden kaavojen ja mallien esittäminen informaation puolesta muutenkin staattiselle kielimallille ei ainakaan anna toivottua lopputulosta.
Ihmiset julkaisevat vain menestystarinat, mutta todella arvokkaat tiedot tulevat siitä, kun joku yrittää jotain, joka ei toimi, ja silti lopulta löytää keinon, miten korjata sen. He kuitenkin julkaisevat vain onnistuneen lopputuloksen, eivät prosessia, joka johti onnistumiseen.
Hyvänä esimerkkinä tästä on myös tunnettu “marmorikuula kahvikupissa” testi, jossa kielimallille ensin kerrotaan, että marmorikuula laitetaan kahvikuppiin, viedään se sitten tasaiselle pöydälle, käännetään nopeasti kuppi nurin ja lopuksi asentoa vaihtamatta viedään kuppi mikroaaltouuniin. Sen jälkeen kielimallilta kysytään, missä marmorikuula on. Lähes poikkeuksetta kaikki kielimallit epäonnistuvat kertomaan oikean vastauksen ja vastaavat, että marmorikuula on mikroaaltouunissa kupissa. Tämänkin voi ajatella johtuvan siitä, että emme ole kuvailleet tällaisia fysiikan lakeihin liittyviä tapahtumia tarpeeksi yksityiskohtaisella tasolla, jolloin kielimalleilla ei ole edellytyksiä vastata oikein. Vasta kun löydämme ne sokeat alueet, jotka vaativat kuvauksen ja jollain tavalla teemme systemaattisesti sen työn, saattaisi kielimalli saada kuvan maailman syy-seuraussuhteista ja muistaa kysyttäessä, miten tilanteissa käy.
Monet tahot varmaan kuumeisesti jo yrittävät ratkaista tätä ongelmaa ja pyrkivät dokumentoimaan niin paljon kuin mahdollista hiljaisesta tiedosta eksplisiittistä. Miljoonat YouTube-oppituntivideot saattavat jo olla osa tätä muutosta, kunhan ne saadaan vain sulautettua kielimalleihin. Meillä on siis tapoja parantaa AI:ta, mutta emme voi odottaa välitöntä älyn räjähdystä, jos se kaikki vaatii uudelleen koulutusta ja ihmisasiantuntijoiden interventiota. Sitten kun ja jos tämä kaikki onnistuu, niin loppuisiko matemaatikoiltakin työt? Taon mukaan, ihmismatemaatikot siirtyisivät tekemään töitä korkeammalla matematiikan abstraktiotasolla. Ei ongelmaa.
Loppupohdintaa
Nämä lähestymistavat eivät ole ”maagisia” ratkaisuja. Mira Murati, OpenAI:n teknologiapäällikkö sanoo, että heillä ei ole mitään jättimäistä läpimurtoa kulissien takana odottamassa. Heillä on nykyiset kyvykkäiksi todetut mallit, jotka eivät paljoakaan eroa siitä, mitä julkisesti on saatavilla ilmaiseksi. Mutta heidän tavoitteenansa on täysin erilainen tapa tuoda teknologia maailmaan kuin olemme historian aikana tehneet.
Tämän ei tarvitse olla “kaikki tai ei mitään”-asetelma. Kuten Chollet sanoo, se voi olla lähestymistapojen yhdistelmä, joka ratkaisee esimerkiksi ARC-AGI tehtävät, ja johtaa todella yleistekoälyyn. Ihmiset, jotka voittavat ARC-AGI-kilpailun, saattavat esimerkiksi yhdistää syvän suunnittelun paradigman ja diskreetin hakulausekkeen yhdeksi elegantiksi ohjelmaksi.
Aihe, jota ei kuitenkaan usein käsitellä näissä yhteyksissä on itseasiassa vanha filosofinen ongelma siitä, että tiedämme ihmisestä itsestä. Tunnemmeko lopulta tarpeeksi hyvin ihmisen päättelyyn, uusien ideoiden oivaltamiseen liittyvää mekanismia ja intuitiota, joka on sidottu mielen toimintaan. Mahdottomuus voi lopulta kulminoitua siihen, että koetamme laskennallisilla tavoilla mallintaa sitä, mikä on redusoimatonta. Chollet itseasiassa ajattelee, että ARC-AGI tyyliset tehtävät, joissa neuroverkolle testiksi syötetty tehtävä sisältää tiedollisen aukon täydentämistä vaativan operaation, se ei ratkeakaan laskennallisesti.
Ehkä meidän täytyy tuntea paremmin myös se, mikä on mieli ja tietoisuus, ennen kuin AGI-tavoite voi aueta kokonaisuudessaan. Nimittäin, jos emme kykene määrittelemään ongelmaa tarpeeksi hyvin, ovat parhaimmatkin ratkaisut tuuliajolla ja joudumme tyytymään satunnaisesti eteemme osuviin uuden tiedon palasiin ja keksintöjen saarekkeisiin. Tässä epävarmassa tilanteessa meidän täytyy myös pohtia eettistä ja yhteiskunnallista vastuusta sekä tehdä lopulta valintoja, jotka eivät ole helppoja. Helpompaa olisi antaa laivan seilata sinne, minne se kulloinkin sattuu viemään, mutta sekin on valinta. Onko se oikea?
PostScript 1: Jos haluat käyttää aikaa opiskella aihetta syvemmin, niin suosittelen katsomaan Machine Learning Street Talkin uusimman videon Chollet’s ARC Challenge + Current Winners, julkaistu 19.6.2024
PostScript 2: OpenAI:lta toissaviikolla eronnut Ilya Sutskever on ilmoittanut 19.6.2024 pystyttäneensä startupin, jonka tavoitteena on – ei enempää eikä vähempää kuin turvallinen superintelligenssi!
PostScript 3: Anthropic julkaisi 20.6.2024 uusimman version Claude 3.5 Sonnet-kielimallista, josta on tullut heidän tämänhetkinen lippulaivamallinsa, ja joka alustavien suorituskykytestien mukaan luultavasti nousee ainakin hetkeksi maailman johtavaksi kielimalliksi. ARC-AGI-haasteen kannalta tämä tuskin muuttaa tilannetta mihinkään suuntaan.
Voit ladata tämän artikkelin koneellesi lukemista varten PDF-tiedostona seuraavasta linkistä: AGI – Yleistekoäly: Totta vai tarua, nyt vai huomenna?
